Proven Savings
at Scale
Every number below is verified at the server plug using a state-of-the-art power analyser — not estimated, not simulated.
llama.cpp
AI Inference Is Energy-Hungry
On a cutting-edge workstation GPU, each generated token carries a significant energy cost. With millions of tokens processed daily, that adds up fast. And without active optimisation, both CPU and GPU hardware are left running at full speed regardless of actual workload demand.
vLLM serving Gemma 4 31B was targeted with 1–60 concurrent requests.† Every data point is the average of 20 independent runs. vert-suite operates under a self-imposed SLA of no more than 10% throughput reduction vs. the unmanaged baseline.
* All Watt-second readings measured at the server wall-socket. Test system: NVIDIA RTX Pro 6000 Blackwell (96 GB VRAM), 24-core workstation, 128 GB RAM, 2,050 W PSU.
† Results generates employing vLLM version 0.20.1 (CUDA 13.0), request's max_tokens set to 500 to prevent queuing -- thus focussing on the specifics of the GPU scaling behaviour.
vert-suite
A production-ready software platform for autonomous GPU/CPU efficiency orchestration — inference engine agnostic, with no hardware changes, no application modifications, and no manual tuning required.

Autonomous CPU/GPU Optimisation
Autonomous bare-metal GPU and CPU management for AI/LLM workloads. Empirically validated energy savings of over 30% per token — with no changes to your application or inference stack.

Continuous SLA Spectrum
Specify your maximum acceptable throughput reduction. vert-suite automatically scans the GPU/CPU operating envelope and locks in the profile delivering the deepest energy savings within your constraint.

Green & Cost-Efficient
Reduce OpEx, extend platform lifespan, and lower your infrastructure's carbon footprint — without replacing or upgrading hardware.

Deep Monitoring with eBPF
Leverage eBPF for deep system observability with minimal operational disruption — complemented by physical out-of-band telemetry for independent power validation.

Zero-Trust, Kubernetes-Native
Least-privilege agents, just-in-time capabilities, and mTLS-secured control-plane traffic. Transparent telemetry with out-of-band validation for full auditability.

Seamless Integration
Inference engine agnostic — validated on vLLM and llama.cpp, and compatible with other leading engines. One inclusive library, cross-platform, cross-Linux/K8S distribution, deployable in minutes with no operators, scheduler extensions, or YAML modifications.
The industry standard is to hand over the keys to the kingdom — permanent, unconditional root access to your kernel, drivers, and hardware. You shouldn't have to compromise your cluster's security just to run your compute efficiently.
Zero-Compromise Security Architecture
vert-suite is built on a strict principle of minimal authority. Instead of deploying a privileged monolith, the architecture is physically split — a standard unprivileged worker that requests just-in-time access only when needed, and only for the exact duration required.
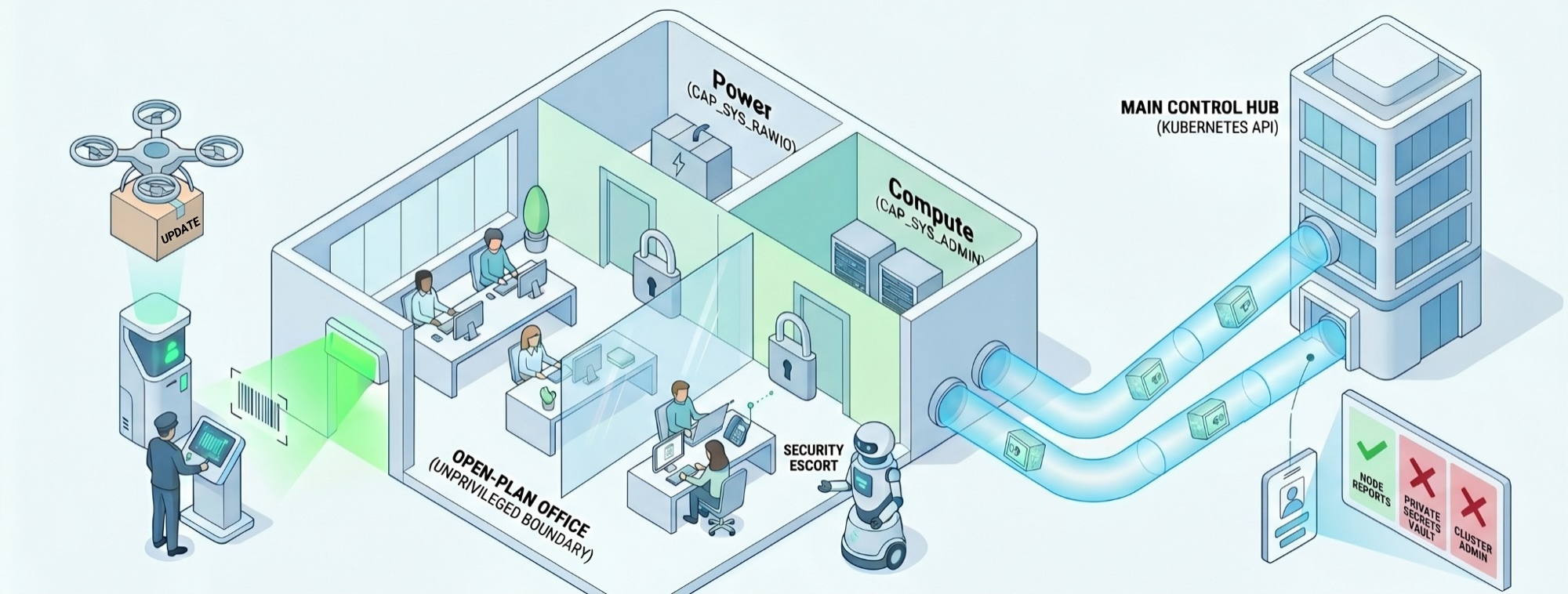
Public key at a terminal — signature verification before any agent is admitted.
Main agent operates as a standard worker within an unprivileged boundary — CAP_SYS_RAWIO and CAP_SYS_ADMIN never granted permanently.
A Security Escort briefly unlocks the required resource, completes the exact task, and immediately relocks — no standing privileges.
All control-plane traffic is encrypted via mTLS tunnels — no plaintext communication between components.
Digital identity verification prevents any component from operating outside its authorised scope.
Install vert-suite
No YAML changes, no Kubernetes operators, no code modifications to your inference stack.
Set Your SLA
Tell vert-suite your maximum acceptable throughput reduction. It autonomously scans the full GPU/CPU operating envelope.
Savings Start Immediately
Real-time CPU/GPU co-optimisation locks in the deepest energy savings within your constraint.
You Set the Constraint.
We Find the Optimum.
vert-suite does not offer a fixed menu of profiles. It offers a continuous spectrum. Simply tell the software the maximum throughput reduction you can accept — say, no more than 10%, 15%, or 20% — and it automatically identifies the optimal GPU/CPU operational mode to deliver the deepest possible energy savings within that constraint.
Three example datapoints — any point on the spectrum is achievable
Minimal Impact
The software identifies the energy-saving profile that keeps throughput within 10% of baseline. Deep savings with near-transparent operational impact.
Sweet Spot
A marginal additional throughput budget unlocks significantly deeper energy reductions. Consistently the highest-value point on the spectrum across all tested models.
Maximum Efficiency
Accepts a larger throughput trade-off to push energy savings to their maximum. Ideal for cost-capped batch workloads where latency is not time-critical.
Comprehensive Model Benchmarks
Five leading open-weight models. Three SLA profiles. All energy independently verified at the server wall-socket using a state-of-the-art power analyser — against unoptimised SotA baselines.
* All Watt-second readings measured at the server wall-socket on a single NVIDIA RTX Pro 6000 Blackwell GPU server.
| Model | Params | SLA Profile | Energy Saved | Ws/token (opt.) | Throughput | TPS Δ |
|---|---|---|---|---|---|---|
| Llama-3-70B-Instruct · Q8_0 | 70B | ≤10% TPS | −28.83% | 27.87 Ws/t | 19.97 tps | −2.87% |
| Llama-3-70B-Instruct · Q8_0 | 70B | ≤15% TPS ★ | −33.84% | 25.90 Ws/t | 19.50 tps | −5.17% |
| Llama-3-70B-Instruct · Q8_0 | 70B | ≤20% TPS | −35.99% | 25.06 Ws/t | 18.02 tps | −12.34% |
| Qwen2.5-72B-Instruct · Q8_0 | 72B | ≤10% TPS | −29.60% | 28.75 Ws/t | 19.39 tps | −2.86% |
| Qwen2.5-72B-Instruct · Q8_0 | 72B | ≤15% TPS ★ | −34.30% | 26.83 Ws/t | 18.94 tps | −5.11% |
| Qwen2.5-72B-Instruct · Q8_0 | 72B | ≤20% TPS | −36.52% | 25.93 Ws/t | 17.48 tps | −12.42% |
| Qwen3-32B · Q8_0 | 32B | ≤10% TPS | −28.07% | 13.32 Ws/t | 39.86 tps | −5.17% |
| Qwen3-32B · Q8_0 | 32B | ≤15% TPS ★ | −32.58% | 12.49 Ws/t | 38.38 tps | −8.72% |
| Qwen3-32B · Q8_0 | 32B | ≤20% TPS | −33.75% | 12.27 Ws/t | 34.18 tps | −18.70% |
| Qwen3.5-27B · BF16 | 27B | ≤10% TPS | −26.59% | 19.82 Ws/t | 26.13 tps | −5.88% |
| Qwen3.5-27B · BF16 | 27B | ≤15% TPS ★ | −31.16% | 18.58 Ws/t | 25.32 tps | −8.80% |
| Qwen3.5-27B · BF16 | 27B | ≤20% TPS | −31.49% | 18.50 Ws/t | 22.82 tps | −17.81% |
| Qwen3.5-35B-A3B · BF16 | 35B MoE | ≤10% TPS | −19.25% | 4.22 Ws/t | 103.11 tps | −10.01% |
| Qwen3.5-35B-A3B · BF16 | 35B MoE | ≤15% TPS ★ | −20.16% | 4.18 Ws/t | 99.28 tps | −13.36% |
| Qwen3.5-35B-A3B · BF16 | 35B MoE | ≤20% TPS | −20.65% | 4.15 Ws/t | 94.82 tps | −17.25% |
Baseline: NVIDIA RTX Pro 6000 Blackwell · llama.cpp · ★ = recommended "sweet spot" profile. All readings at wall-socket.
Optimising Autonomous AI Agents
Continuous, zero-intervention AI agent loops create a sustained, demanding inference load. We validated vert-suite in exactly this scenario — using Claude Code acting as an autonomous coding agent running non-stop research iterations on a dedicated GPU server.
| Metric | Without vert-suite | With vert-suite | Change |
|---|---|---|---|
| Avg. server power (wall-socket) | 781 W | 459 W | −41% |
| Energy per token | — | — | ~−32% |
| Throughput impact | baseline | reduced | ~−12% |
Stack: Claude Code · RTX Pro 6000 Blackwell · vLLM · Gemma 4 31B · vert-suite. Power measured at server wall-socket.
What 30% energy savings means in practice
Average UK commercial electricity rate: 25.5p/kWh · 24/7 continuous operation · Savings scale linearly with fleet size
| Server tier | Peak draw | Annual energy cost | Annual saving (30%) | Cost after saving |
|---|---|---|---|---|
| Workstation | 2.5 kW | £5,585 | £1,675 | £3,910 |
| Mid-Range Server | 6.25 kW | £13,961 | £4,188 | £9,773 |
| Enterprise Server | 10 kW | £22,338 | £6,701 | £15,637 |
Based on UK commercial electricity rate of 25.5p/kWh · 24/7 continuous operation · savings scale linearly with fleet size.










